
SEOツール、ひいては自社データを最大限に利用できないことが多いのは、利用方法に問題があることが多いです。これは、利用しているツールの数が多く、作業量が膨大な場合に特に当てはまります。特定のツールの機能を十分に調べる時間がなく、結果として各ツールから限られたレポートのみ使用することが多いと思われ、これによりサイトのパフォーマンスを監視する作業がルーティン化し、深い分析ができなくなる可能性を孕んでいます。
ツール確認のルーティン化は効率的であると思われるかもしれませんが、これはそのツールの利用料金に含まれる機能のうちの表面的な機能のみを利用していることになります。これは、DeepCrawlにも当てはまります。DeepCrawlのクローラーでは、管理画面で確認できるクロールのスケジューリングや各変更点の確認以外にも、はるかに多くのことが可能となります。
カスタム抽出とは?なぜ便利なのか?
SEOツール、特にWebサイトクローラーを活用する最善の方法の1つは、カスタム抽出を利用することです。この機能を使用すると、Webサイトのコア部分に直接アクセスし、HTMLから最も重要な情報を取得できます。カスタム抽出は、サイト上の大量のコードをふるいにかけ、必要なデータのみを整理された形で返します。この機能の使用方法を知っていると、DeepCrawlははるかに柔軟なツールとなり、より多くの粗いデータを処理できます。

レポートではサイトの健全性とパフォーマンスに関する詳細な情報を提供していますが、それ以上にサイトの詳細を把握したい場合には正規表現をご利用ください。カスタム抽出は、各サイトの要件に応じてカスタマイズされるものであり、すべてのユーザーに適したサービスという性質のものではないため、貴社サイトに最適な正規表現を作成することは十分に価値があります。
正規表現とは?
正規表現が実際に何であるか、そして正規表現に何ができるか完全に理解していない場合、以下をご参照ください。正規表現は検索のパターンを作成する手法です。を表し、検索パターンを作成する手段になります。正規表現の文字列を使用して、Webサイトのコードの特定の部分を特定のセクションを照合、場所を特定できます。基本的に正規表現は、はるかに洗練されたCtrl + F(またはCmd + F)関数として使用できます。
正規表現には、クロールに含む/含まない設定がされているURLのマッチングといった抽出以外の利用方法もございます。Googleアナリティクスは正規表現の一致もサポートしており、ツール内でレポートをフィルタリングする際に非常に役立ちます。
さまざまな正規表現がありますが、DeepCrawlではRubyを使用しています。
作成した検索パターンは、見つけたコードのスニペットを意味のある分かりやすい方法で示すSEOツールと組み合わせることができます。たとえば、DeepCrawl内で正規表現を使用してカスタム抽出クエリを作成し、サイトにコード化された製品価格を検索すると、価格がリスト化された便利なページリストを抽出することができます。
正規表現の使用方法
推奨されるカスタム抽出の例を説明する前に、正規表現の使用関するおさらいをしましょう。正規表現を理解し作成することは、最初は非常に気の引ける作業ですが、様々な文字や機能の基本さえ理解してしまえば、すぐに正規表現を使いこなせるようになります。このガイドを使って正規表現を使う前の基礎を身に付けましょう。
正規表現を正しく使用するための鍵は、ソースコードに表示されるパターンの確立にあります。すべてのサイトのコーディングは異なっており、全てのカスタム抽出に関する万能なガイドはありません。唯一全てに共通する文字列は、Googleアナリティクスのコードタグなどあらゆるサイトに同じ形式で現れるもののみです。
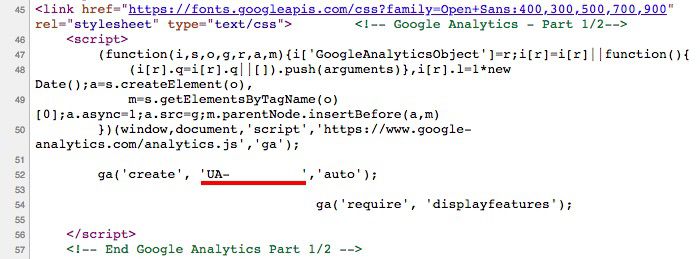
サイト固有のコードのパターンを識別する最善の方法は、各テンプレートの例を取得したり、要素を検証したり、ページソースを確認したりすることです。
Rubularは、テンプレート分析結果に基づいて作成された正規表現の文字列を試行およびテストするための優れたツールです。このツールはRubyテストもサポートしているため、DeepCrawlでクロールしたい全ての対象をテストするのに最適です。
カスタム抽出の例
カスタム抽出(本国版のページへ遷移します)でできることは多くあります。すべてのユーザーDeepCrawlを最大限に活用できるようにするため、サイトの技術的な健全性をさらに調査するためにおすすめの使用例をリストにまとめました。それでは、クロールで発見できるデータを見ていきましょう。

以下が、カスタム抽出の例です:
DeepCrawlアカウントにログインまたは 無料トライアルにサインアップしてからプロジェクトを作成し、自社サイトでこれらの例をお試ください。クロール設定の4番目のステップにある詳細設定にて、カスタム抽出に関する設定を行うことができます。
独自の正規表現の作成に困った場合は、こちらにご連絡ください。また、ご質問、ご要望等ございましたらお気軽にお申し付けください。
以下、他の例に関する正規表現文字列を作成するアイデアをご提供する目的でカスタム抽出の手順例を挙げるため、ソフト404エラーを把握するのに役立つ正規表現文字列を正確に記述する方法を説明いたします。
ソフト404エラー
DeepCrawlは、ウェブサイトのクロールを実行したときに遭遇するステータスコードについてレポーティングを行います。ただし、カスタム抽出は、サーバーからのレスポンスを超えて、ユーザーと検索エンジンがアクセスした際に表示されるページの詳細を解析する手法となります。
ソフト404エラーの場合には、さらなる調査が必要となる場合があります。これはページが見つからないか、ページのコピーがコンテンツがないことを示しているがサーバーが200 “OK”ステータスコードで応答する場合に発生します。
「リクエストしたページが見つかりませんでした。」のような一般的なページ上のエラーメッセージに関して、そのHTMLマークアップは次のようになっている可能性があります。
以下の単純な正規表現を使用することで、HTMLを使わずに完全なメッセージを取り込むことができます:
この仕組みは以下の4点を参照してください:
- 最初の2文字である「>(」は、<span>や<div>といったHTMLタグの開始地点となる括弧を探し、そこから取り込みを開始します。
- 「[^<]*?」という表現は、HTMLタグの開始を示す括弧ではない0以上の文字をキャプチャします。言い換えると、ターゲット文字列の前にあるあらゆるテキストが該当するということになります。
- 「見つかりませんでした」は、特定のターゲット文字列を参照します。
- 「[^<]*)<」は、次の閉じ括弧が見つかるまで、ターゲット文字列に続く残りのテキストをキャプチャし続けます。
「そのURLはもう存在しません」や「アイテムは現在在庫切れです」などのさまざまなエラーメッセージがサイトに表示される場合、キャプチャされないグループとして、「|」や、「(?:」と「)」で囲まれた代替ターゲット文字列を使うことにより、ターゲットとなる文字列を追加することができます。
- 「(?:見|み)」 … 「見」または「み」の単語を検索します。
- 「?」 … オプションのスペース文字を探します。
- 「(?:つかり|つけられ)」 … 「つかり」または「つけられ」と続く単語を検索します。
- 「ませんでした」 … 「ませんでした」の正確な文字列で上記と一致するものを検索します。
本当に基礎部分をカバーする必要がある場合は、特定の文字がHTMLとしてエンコードされる可能性があることを忘れないようにしてください。
正規表現とカスタム抽出がどのように機能するかをしっかり理解いただけたと思いますので、それらの利用方法や、サイトに関して得られる洞察に関して更に詳しく見てみましょう。
eコマース製品情報
数え切れないほどの製品数があり、さまざまなチームがCMSにアクセスしているように見える場合、サイトの刻々と変化するeコマース製品データを追跡することは不可能に思えるかもしれません。自動化された方法でWebサイト上の製品の全体像をより正確に作成するために、カスタム抽出を使用して本当に必要なデータをスクレイピングできます。そのための最善の方法は、いくつかの製品ページとそれらのメタデータまたはスキーマのレイアウトを見て、より広いコードのパターンを見つけることです。
たとえば、ある製品ページで、特定の要素の「検出」をクリックしたり、ソースコードを見たりするとき、作成したい正規表現の文字列に関係するコードに焦点を合わせることができます。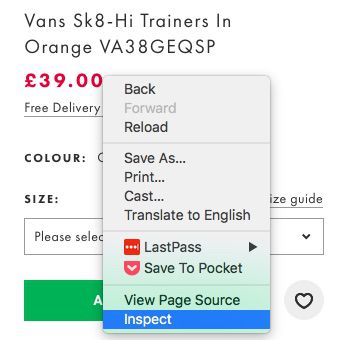

以下は、製品から収集できる詳細の例です。
在庫状況
ユーザー体験の中で最もユーザーにフラストレーションを与える要素の1つは、在庫切れの製品ページです。

カスタム抽出を使用すると、サイトの在庫切れ製品のボリュームと在庫切れのある商品のURLを追跡できます。これにより、除外する製品を把握することができます。アナリティクスデータやGoogle Search Consoleと統合することにより、インプレッションと訪問者をマッピングして、どのユーザーが在庫切れ商品のページを見ているか確認することもできます。

クローラを使用して廃止された製品ページのタブを維持すると、内部的にリンクされていない孤立したページを見つけることもできます。収集されたデータは、リダイレクトやnoindexを使用したり、在庫のある関連商品を紹介する部分をページに追加したりするなど、在庫切れの製品を処理する現在のアプローチを評価するのに役立ちます。
カテゴリページの商品数
内容の薄いカテゴリページは、ECサイトにとって一般的な問題であり、在庫状況は変化するという性質を考慮すると、これは当然の問題といえるでしょう。ECのカテゴリページは、提供する製品と同じくらい強力なものですが、往々にして売り切れるか、サイトから削除される少数の製品を掲載しているような、非常に簡素なカテゴリページとなっている場合があります。
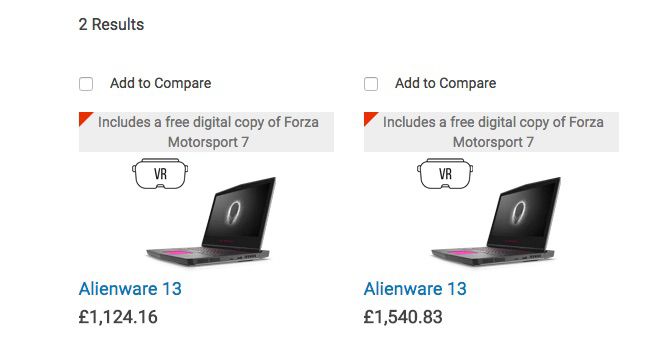
カスタム抽出を使用して、サイト上の空のカテゴリページ数、およびこれらのページの処理に関する現在の挙動を監視できます。例:インデックスされていない、リダイレクトされている等
追加の商品詳細
以下は、カスタム抽出を使用して取得できるその他の製品詳細の一部です:
- 価格
- 製品のシリアル番号/ SKU
- カテゴリーコード
- 製品の寸法とサイズ
- 配送の見積もり
コンテンツ
コンテンツ監査の編集に役立つ記事からデータを抽出する必要がある場合や、コンテンツの特定のセクションを更新する必要がある場合には、regexによりサイトの各ページからほしいテキストをスクレーピングすることが最善の方法となります。
複数のカスタム抽出から収集されたデータを結合すると、より監査に役立つデータを収集できます。たとえば、コンテンツが属するセクションまたはカテゴリと作成者のデータを収集し、これをGoogleアナリティクスなどの他のデータソースと組み合わせてトラフィックメトリックを表示する場合、すべてのデータをピボットして、コンテンツが有力かどうか判断できます。これは、コンテンツの管理と分析にカスタム抽出を使用する方法の表層部分に過ぎず、さらなる可能性を秘めています。
表現方法
カスタム抽出を使用すると、「Black Friday 2017」などの特定の単語やCTAを更新し続ける必要のある表現を見つけることができます。同様に、更新する必要がある音声ドキュメント内の特定の単語を含むページを見つけてブランドトーンを新しくしたり、ブランド名のスペルが間違っているものを見つけたりすることができます。
テキストの特定のインスタンスを見つけるだけでなく、コンテンツをより完全な形で分析したい場合は、テキストのセクション全体を抽出できます。ただし、より広範なコンテンツ分析を行いたい場合は、複製されたコンテンツと欠落しているコンテンツに関する詳細なレポートを提供します。
著者名
カスタム抽出を使用して著者名を検索し、どのコンテンツがどのライターによって作成されたか追跡できます。チーム内のさまざまなコンテンツライターによって作成されたコンテンツの数を比較したり、Googleアナリティクスのトラフィックデータなどの他のソースからデータを上乗せすることで、どのライターが最も魅力的でパフォーマンスの高いコンテンツを作成しているかを確認したりすることもできます。
コンテンツカテゴリ
カスタム抽出を使用してコンテンツのカテゴリを抽出することもできます。例えばタグやカテゴリのサブフォルダーで投稿を区別しているかに関わらず可能です。この情報を抽出することで、各カテゴリ内で公開されている記事の量を測定したり、他のツールの分析データと検索行動データを掛け合わせて、サイトで最もパフォーマンスの高いコンテンツカテゴリを評価したりできます。また、この情報を公開日と組み合わせて、コンテンツの作成と消費(閲覧)の傾向を効果的にマッピングすることもできます。

公開日
記事の発行量を長期的に把握したい場合は、カスタム抽出を使用して記事の発行日を引き出すことができます。このデータは、コンテンツの季節性をマッピングするために使用できます。また、Googleアナリティクスのトラフィックメトリックと組み合わせて、読者のエンゲージメントを経時的に調べることもできます。
最終更新日
最終更新日は、トラフィックがあるがしばらく更新されていない古い記事のような、コンテンツの更新が必要なページを強調して表示するのに役立ちます。また、最後に更新された日付をトラフィック指標と合わせることで、サイトに利益を与えていない古いページを見つけ出すことも可能になります。
カスタム抽出を使用してページの最終更新日を取得するには、2つの方法があります。ニュースサイトでは、異なるソースからの引用またはコメントで記事が更新されたときに、最終更新日が手動で追加されることがあります。この場合、当日付よりも前のテキストパターンを検索する文字列を作成します。これは「最終更新日」や「修正日」といった表現となります。一方、最終公開日はCMSによって自動的に生成されるため、日付の「検査」をクリックして、正規表現を記述するために必要なコードの文字列を見つけます。
連絡先
さまざまな理由で、サイトから連絡先の詳細を取得する必要がある場合があります。個別の連絡先詳細が記載された多くの店舗の場所と対応するページがあり、それらの正確性を確認するためにリスト全体を検証する必要がある場合があります。例えば、ブロガーサークルのサイトを分析してインフルエンサーの調査を行ったり、たとえばリストを更新するために連絡先の詳細を知りたい場合などのケースもあります。
画像
画像検索は、検索トラフィックの強力なソースになる可能性がありますが、画像が正しい方法で最適化されている場合にのみ適切に利用できます。カスタム抽出を使用すると、サイト上の画像に焦点を合わせ、画像の監査を自動で実行することができます。
画像のAltタグ
検索エンジンは画像altタグを使用して、画像をよりよく理解しようとします。これは、画像検索においてトラフィックを増やす目的でサイトを最適化するために、画像altタグを有効に使っていることが基礎的な前提となっていることを意味しています。便利なことに、DeepCrawlでは事前にデフォルトとしてカスタム抽出として「画像altタグがない」という指標を提供しており、正規表現を作成するなど追加で必要なリソースは発生しません。

画像サイズ
ECサイトでは、製品画像は通常、一定のサイズでアップロードする必要があります。これは、正規表現の文字列を記述してこの特定の情報を含む画像を検索することにより、すべての製品画像のリストを編集し、これを「altタグを見つける」などの他のカスタム抽出と組み合わせることができるようにするという目的のためです。
マークアップ
マークアップと構造化データには、SERPスニペットを競合他社より目立たせる、アンサーボックスと音声検索結果の通知、GoogleがWebサイトをよりよく理解できるように(本国版のページへ遷移します)するなど、多くの利点があります。これらすべてを考慮した上で、GoogleのSERPを有効活用するためにサイトのマークアップの概要を把握して、正しく実装されていることを確認することが重要です。
カスタム抽出により、マークアップされたページを識別でき、マークアップされた情報を抽出することもできるため、所有しているさまざまなプロパティに加え、それらプロパティを分類したカテゴリを確認することができます。
スキーマ
ここで様々なスキーマのリストを見ることが可能であり、組織スキーマ、製品スキーマなどの正しい構造を見つけることができます。これらのガイドでは、正規表現のクエリを作成するのに役立つさまざまなプロパティの公式の表現を確認することが可能です。たとえば、さまざまな製品ブランドを調べたい場合は、ブランドのプロパティに関するコードを抽出する必要があります。
以下に示すように、microdataやJSON-LDなど、スキーマは様々な方法でサイトに追加できることも忘れないようにしてください。サイトのソースコードを確認して、サイトのスキーマがどのように実装されているかを確認することで、作成するべき正規表現の文字列を考える参考にしてください。
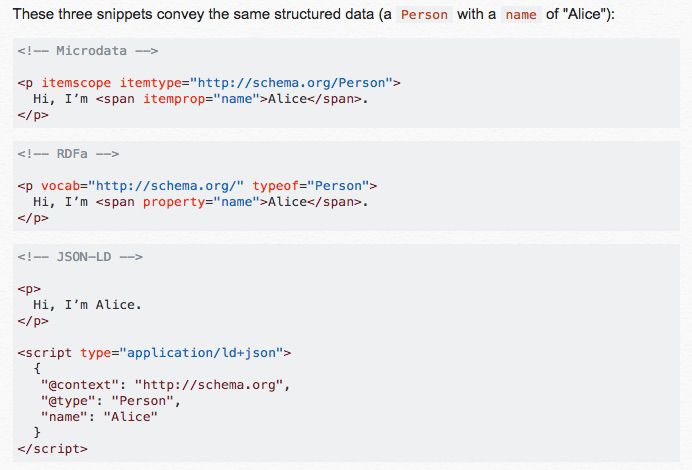
ソース:https://softwareengineering.stackexchange.com/questions/328567/how-does-microdata-rdfa-compare-to-json-ld
パンくず
基本的にパンくずは、ユーザーにサイトをナビゲーションするための方法のように思えるかもしれませんが、サイトのパンくずから、たくさんの興味深い洞察を集めることができます。これはサイトの分類に関する分析に影響を及ぼすだけではなく、サイトを大規模に監視できるように明確に分割することにも役立ちます。
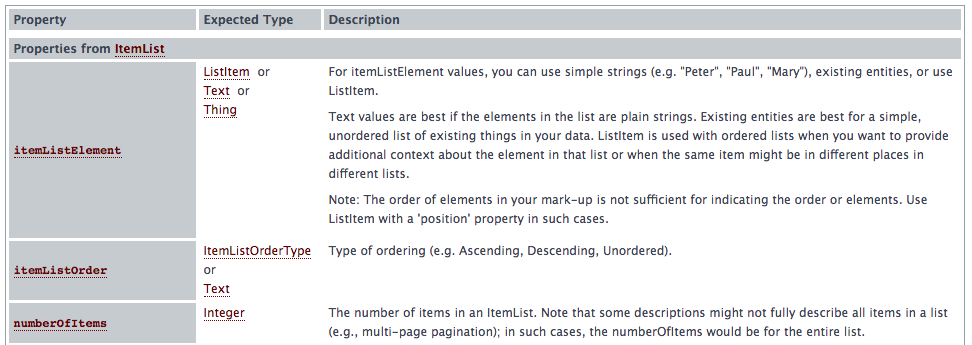
パンくずをマークアップするのが理想的です。Schema.orgのガイドラインを使用してこれを行う場合、“itemListElement”などの明確に定義されたプロパティを見つけて、正規表現クエリに含めることができます。
レビュー
自社商品の人気度をより良く理解する目的で個々のレビューまたは集計レビューを評価するために、カスタム抽出を使用してレビュースキーマを引き出すことができます。これを使用すると、ベストセラーであるがレビューがない製品、またはレビューが不十分な製品を相互に参照して、サイトのどの領域を改善する必要があるかを判断することができます。
schema.orgを使用して、製品マークアップのガイドラインを見つけることができます。製品ごとに異なるレビュー評価を収集する場合は、たとえば、“reviewRating” プロパティのコードを抽出する必要があります。
トラッキングとイベントタグ
サイトにトラッキングコードとイベントコードを設定すると、コンバージョンに関する重要な洞察が得られ、ユーザー体験をテストすることができます。サイト上の体験を顧客に与える最善の方法を示す重要なテストまたは監視を実行している場合には、実装したコードとタグが実際に配置され、正しく機能していることを確認する必要があります。
これらタグの一部はHTMLに手動で追加されますが、JavaScriptを使用して挿入されるものもあります。つまり、カスタム抽出をこのように機能させるには、レンダリングされたクロールを使用する必要があります。
Googleアナリティクスコード
Googleアナリティクス(GA)トラッキングは非常に一般的であるため、デフォルトで設定されているカスタム抽出ルールの1つとなっています。これを有効にしてサイト全体のクロールを実行することで、サイト上のすべてのページに固有のGAコードが存在することを確認できます。これにより、ウェブサイトのトラフィックと顧客のブラウジング動作を確実に追跡できるようになります。
![]()
イベント追跡
UAコードが存在することを確認するだけでなく、Googleアナリティクス分析にカスタム抽出を使用できます。また、サイトで追跡している可能性のあるGAイベントを抽出し、ニュースレターのサインアップ、フォームの送信など、正しく実装されていることを確認するためにも使用できます。
Google Tag ManageGoogleタグマネージャー
カスタム抽出を使用すると、サイト全体で実装されているGoogleタグマネージャを確認できます。これは事前に設定されたカスタム抽出ルールの1つでもあるため、次回のクロールの設定が非常に簡単となります。
![]()
Omnitureタグ
誰もがGoogleアナリティクスの追跡に焦点を当てているわけではないため、すべてのトラッキングツールに対応しています。カスタム抽出を使用して、Omnitureトラッキングタグが正しく配置されていることを確認できます。
覚えておくべきこと
カスタム抽出を最も効率的に使用するための鍵は、まず数ページでテストして、ほしい結果が得られることを初めに確認することにあります。これが完了したら、セットアップした正規表現を使用して、サイト全体のクロールを実行してください。
カスタム抽出は非常に便利ですが、特定のテキストまたは情報を抽出するときに誤検出が発生する可能性があることに留意してください。たとえば、お客様が特定の価格を引用しているコメントやレビュー、またはソフト404エラーのような他のページで受け取ったメッセージなど、サイト上でユーザーが作成したコンテンツに意識を向ける必要があります。
私たちはデータで多くのことを達成できますが、最も意味のある結論を下すために、収集したデータの独自の抜き打ち検査と検証を行うことが重要です。
これまでのリストの中に、次回のクロールで試してみたいが正規表現に完全に適合していないものがありましたか?ご連絡頂ければ、お客様のウェブサイトに最適なカスタム抽出のための正規表現を作成し、この機能に関するあらゆるご質問にお答えいたします。
DeepCrawlおよび他のSEOツール内でカスタム抽出をどのように使用しますか?独自のハックやヒントがあれば、ぜひ知りたいのでツイートしてください!
システムの変更
我々のレポートシステムが更新され、データ処理がかつてないほど速くなりました。今回のアップデートでは、クローラーが正規表現を処理する方法にいくつかの変更を加えました。詳細については、こちらのガイド(本国版のページへ遷移します)をご覧ください。
上記のカスタム抽出の例は、正規表現を使用してサイトの健全性と設定をより深く掘り下げることができる方法の表面に過ぎません。ご自身でDeepCrawlを是非試してみてください。お客様のニーズに合わせてカスタマイズされた柔軟なパッケージのご用意がございます。

