
この記事では著者独自の見解から、効果的なSEO施策にとってに不可欠な問題をご紹介します。もちろん、目を引く画像が詰め込まれた魅力的なコンテンツを作成したり、タイトルやaltタグ、その他すべてのSEO専門家が実施する様々な最適化施策には有効なものもあります。しかし、どんなに良いコンテンツを準備しても、クロールバジェットの最適化を行わなければ、スパイダーがそれらを検出することはできません。
クロールバジェットの概要と必要性
クロールバジェットとは、特定の期間においてGooglebotがサイトに対して行ったリクエスト回数を指します。シンプルに言うと、サイトの最新コンテンツをGoogleに伝えるチャンスのことです。
GoogleのGary Illyes氏は、クロールバジェット問題への非常に興味深い対処法を発表(英語)しました。
クロールバジェットは、スパイダーがサイト上のコンテンツを調べるために行うリクエストの回数と関連しています。Gary氏は次のように述べています。”GoogleはURLのリストを作成し、重要度で並び替えを行った上でその後、ボットはリストを重要度が高い順にクロールする。リスト上の全URLをスパイダーがクロールできれば理想的だが、URLのリストが膨大であるがゆえにサーバーの速度を保ったままスパイダーがクロールすることはできないという状況が発生してしまい、そうなると、スパイダーはクロールを停止してしまう。
Googleがクロール対象URLの順番をどのように決定するかについてご説明します。概してそのページのオーソリティ(ページランク)に依存するのですが、他にはXMLサイトマップやリンク等もシグナルとして機能します。つまり、今後GoogleにクロールされるURLの選定プロセス最適化タスクは事実上あなたが握っているということです。では、何から始めれば良いのでしょうか。
Googleサーチコンソールで、Googlebotがクロールしているページ数を確認できます。クロール>クロールステータスに移動すると、Googleがクロールしている平均ページ数の情報を見ることができます。
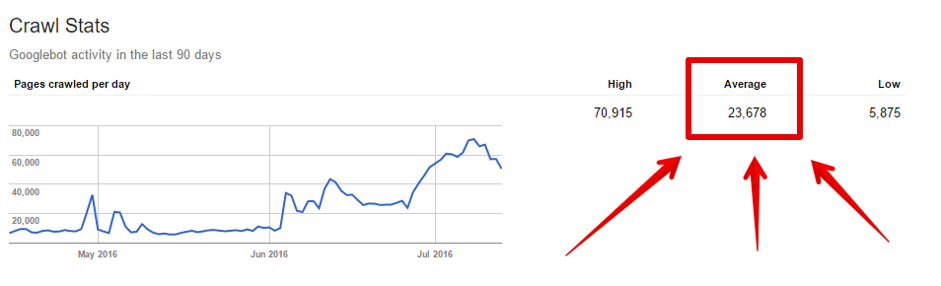
平均値ではありますが、クロールバジェットの最適化プロセスの開始地点として活用しても良いでしょう。
クロールバジェットの最適化の重要性
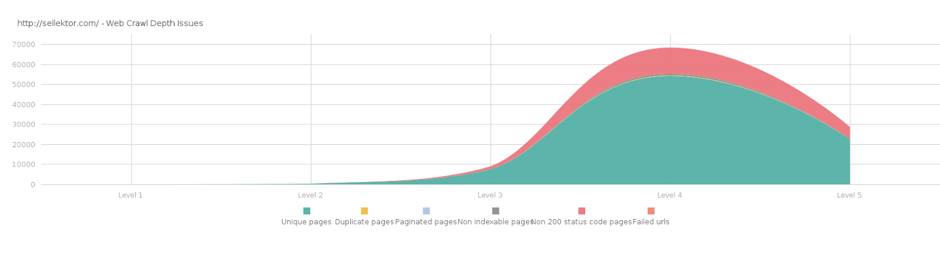
Googleはサイトのページの一定数のみクロールしていて、誤った順でURLをソートする場合があります(こちらが希望する順と異なるという意味)。例えば、収益に繋がらない”About us”ページが、新商品のカテゴリーリストよりも多いクリック数を獲得するいうことがあります。最も適切で最新のコンテンツをGoogleに提供する必要があります。
クロールバジェットの最適化方法
読者の方はGoogleによるクロールを制御する多くの方法をご存知かと思います。そのため、サイトとクロールバジェットの最適化にあたり注力すべきだと著者が考える点をご説明します。クロールバジェットの最適化には、大きく分けて3つのステップがあります。
- サイトの整理
- サイト表示速度の改善
- サーバーログ分析
それでは、これらを詳しく見ていきましょう。
1.サイトの整理

ECサイトはさまざまな面から重複の問題と闘う運命にあります。別のURL上にまったく同じ、またはほとんど同じコンテンツが生成されることが非常に頻繁に発生します。並べ替え、フィルタリング、サイト内検索オプションなどを考えてみるだけでも、それらのすべてがサイト全体としては極めて大規模な重複を招いていることが想像できるでしょう。つまり、URLは常に1バージョンに保つことが重要です。
よくある問題は次のようなものです:
- ①ある商品が異なる複数のURLに存在する。例えば、後者のような配列になるのではなく前者のように商品ページURLにカテゴリーが含まれている場合。
www.domain.com/category-1/category-2/name-of-the-product
www.domain.com/name-of-the-product
- ②商品が2つ以上のカテゴリーに属しており、それぞれのカテゴリーURLパスに商品が掲載されている場合。
www.domain.com/shoes/high-heels/product-name
www.domain.com/woman/high-heels/product-name
カテゴリーページにおいて、同様の問題をよく目にします。
商品のバリエーション(カラー、サイズ等):商品のそれぞれのカラーやサイズ毎に個別のURLがある場合があります。色やサイズ、数量は商品説明の違いでしかないことがほとんどのため、そのURL構造は推奨されていません。以下の画像はその例です。
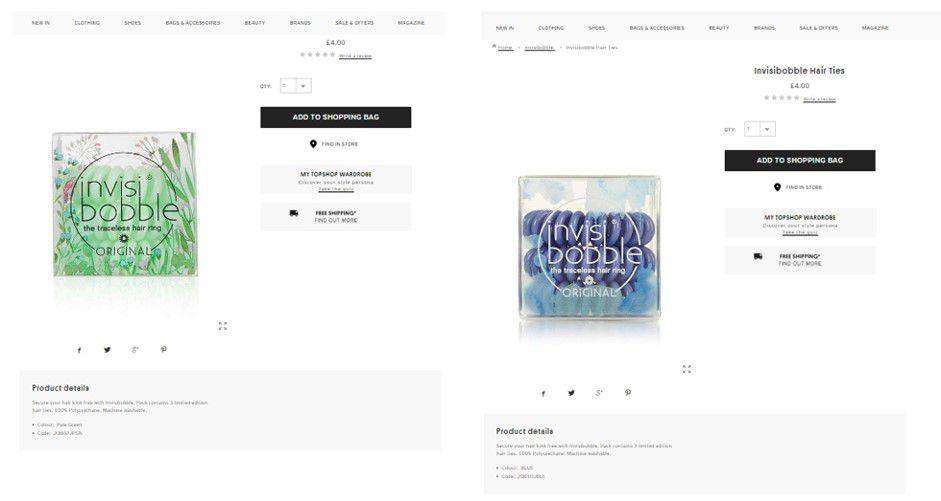
前述の問題はrel=”canonical”やnoindexタグで解決されますが、これらのURLは引き続きクロールされます。Googleはこれらのページを通常ページよりも低い頻度でクロールする(noindexやcanonicalタグがあるかどうかの確認だけ行う)ことを認めていますが、それでもクロールバジェットが浪費されてしまうという問題が残ります。
重複の解消方法
まず始めに、コンテンツ重複が発生している箇所を特定しましょう。DeepCrawlの以下のレポートで、重複ページを確認できます。
- インデックスページ > 重複ページ
- メインコンテンツ > 重複コンテンツ
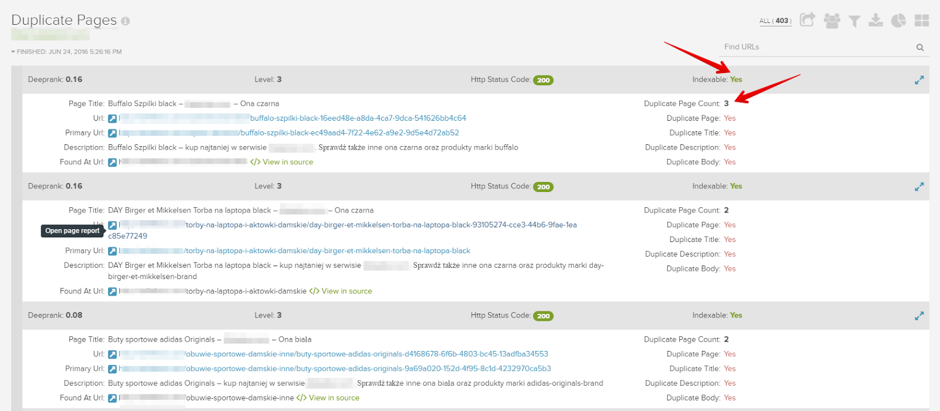
重複を解消するための画一的な方法はありませんが、最も効果的なのは、例えば同商品のバリエーションといった重複の元となる要素を取り除くことです。サイトの一部をインデックスから外す必要がある場合は、まずはページがすでにGoogleにインデックスされているかどうか確認してください。インデックスされている場合、ページのヘッダーにnoindexタグを追加してGoogleのインデックスから不要なURLを取り除いてください。出来るだけ早くページをインデックスから外すためには、一時的なXMLサイトマップを作成して、インデックスから削除したいURLをそのサイトマップに載せてGoogleサーチコンソールに登録してください。問題が解決したら一時的なサイトマップを廃棄し、robots.txtでURLをブロックしましょう。
不正なリダイレクト
リダイレクトとは、SEOにおいて非常に役に立つ方法であり、サイトの移行や再構築、誤ったURLの更新などに活用できますが、正しく実施しないと重大な問題を引き起こしてしまう可能性も孕んでいます。
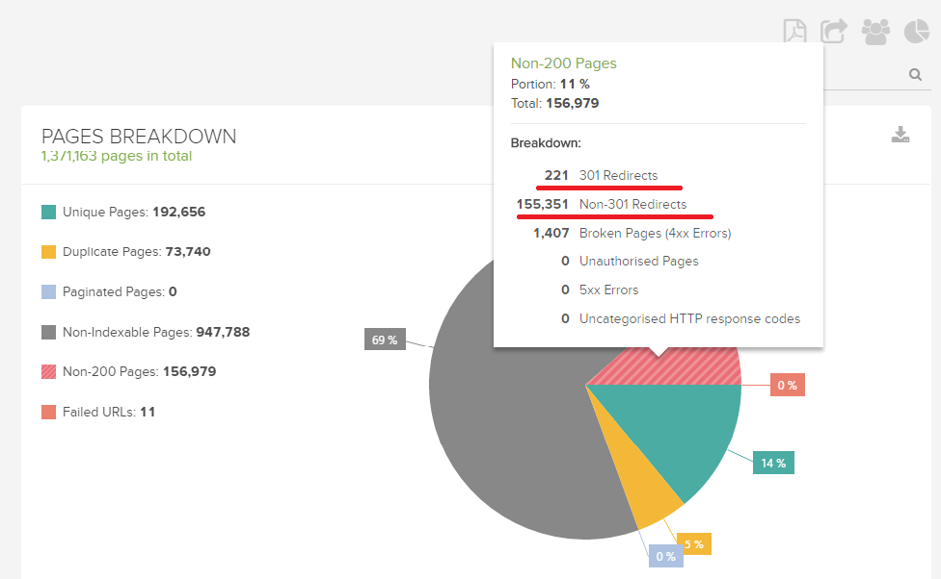
リダイレクトチェーン
リダイレクトチェーンとは、最初と最後のURL間で複数のリダイレクトが発生する場合のことを指します。以下がその例です。:

リダイレクトチェーンの詳細は、プラグインのRedirect PathやDeepCrawlの200以外のページ>301リダイレクトのレポートで確認できます。
Googleのボットは複数回のリダイレクトに対応可能ですが、各リダイレクトが発生することでページランクが阻害されるだけでなく、各リダイレクトURLにをボットがクロールすることで貴重なクロールバジェットが浪費されてしまいます。
404エラーや正規化されていないURLへのリダイレクト
次に多く見られる問題は404エラーや正規化されていないURLへ向けられたリダイレクトです。この状況ではGoogleから無視されるページをGooglebotにクロールさせていることになります。
誤ったリダイレクトの修正方法
サイトの規模が大きくなるほどリダイレクトも複雑化しますが、時々リダイレクト状況を確認してモニタリングしておくと良いでしょう。サイト全体をクロールすると、最も簡単にリダイレクトを確認することができます。DeepCrawlを使用するとボトルネックとなっている箇所の特定に必要なすべての情報を参照でき、この情報を活用することで新しく正しいリダイレクトを設定することができます。
404エラーを返すURLの修正
ここで、404エラーは全く間違いではないということを明確化したいと思います。規模が大きいサイトに404エラーが存在するのは自然なことです。しかし、これらのページも他のページと同様にクロール可能でありページランクを蓄積しているということにご留意ください。クロールバジェットを価値のあるコンテンツページではなく、エラーページに使用するのが有益なことであるはずはありません。
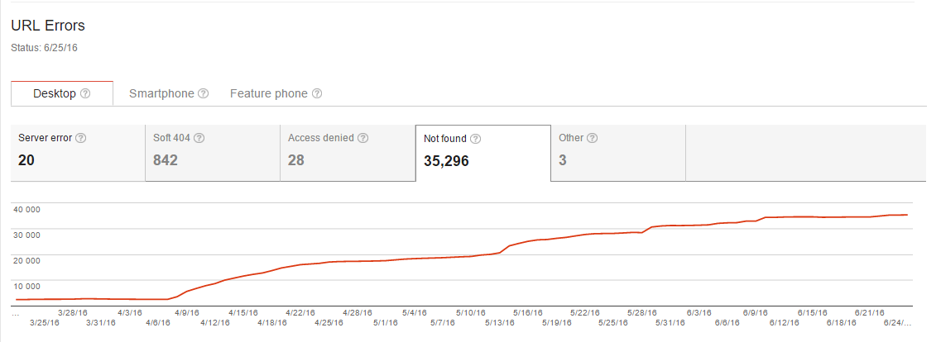
Googleサーチコンソールのクロールエラーレポートで、サイト内で検出された404エラーを確認することができます。リスト(残念ながら1000行のみ)をダウンロードして、リダイレクトに変更可能なものがないか分析できます。404エラーのURLに相当するもしくは類似したユーザーにとって役立つページがないか調べて、見つかった場合は、壊れたURLから新しいURLへリダイレクトを行いましょう。DeepCrawlでURLのステータスコードを調べるだけですべての404エラーページを把握することができます。
robots.txtファイルの最適化
クロールバジェットの最適化において、robots.txtファイルは最も効果的な方法です。robots.txtファイルはクロールしてはいけないURLやディレクトリをボットに伝える指示書になります。そのため、このファイルが正確であることが非常に重要です。
robots.txtでのクロールバジェット最適化方法
クロールさせたくないすべてのディレクトリとURLをrobots.txtに追加してください。誤って重要なページをブロックしないよう注意してください。Googleサーチコンソールのテストツールを使用すると、robots.txtファイルでブロックされている内容を簡単に確認できます。
robots.txtはボットへの命令ではなくあくまで提案であることを覚えておいてください。robots.txtでブロックしたページへ向けられたシグナルをGooglebotが多く検出した場合、Googlebotはrobots.txtが誤って編集されたものだと解釈してしまいます。結果、Googlebotはそのページをクロールしてしまいます。これを避けるために、以下を行なってください。
- robots.txtでブロックされたページをXMLサイトマップから削除する
- ナビゲーションからブロックしたページへのリンクを行わない
- ブロックしたページへの内部リンク、外部リンクを避ける
XMLサイトマップの整理
XMLサイトマップには、Googlebotに最も頻繁に訪問してほしい一番重要なURLを含めるようにしてください。GoogleはXMLサイトマップをクロール対象URLのリスト作成に使用していると認めています。そのため、XMLサイトマップを常に最新に保ち、エラーやリダイレクトが発生しないよう管理しましょう。
フラットなサイト構造の構築
階層が深く複雑なサイト構造は、必要なコンテンツを見つけるために何度もクリックが必要という点でユーザーにとって不親切なだけでなく、特にナビゲーションが効果的に設定されていない場合、ボットにとってもクロールが困難になります。最も重要なページは、常にトップページの出来るだけ近くに配置するようにしましょう。コンテンツをサイト構造において垂直ではなく水平方向に整理すると良いでしょう。
サイト構造の改善方法
まず始めに、現在のサイト構造を可視化しましょう。可視化しなければ、サイトがどれほど深く複雑となっているか気づくことができません。その後、テーマに沿ったリンクを行う、不要な階層を削除するなど、理路整然としたページの再編成を行いましょう。
サイトパフォーマンスの最適化
最近、ページの読み込みが早ければ早いほどユーザーとサイトにとってより良い効果が得られる、ということが繰り返し唱えられています。ユーザーをサイトに留めておくことができるためだけでなく、確実にボットにサイトのクロールをさせることができるため、この指摘は正しいと言えるでしょう。サイトの速度を上げる方法に関して多くの資料が公開されているので、ぜひ活用してください。DeepCrawlの以下のレポートで、パフォーマンスに関する問題の原因を突き止めることもできます。
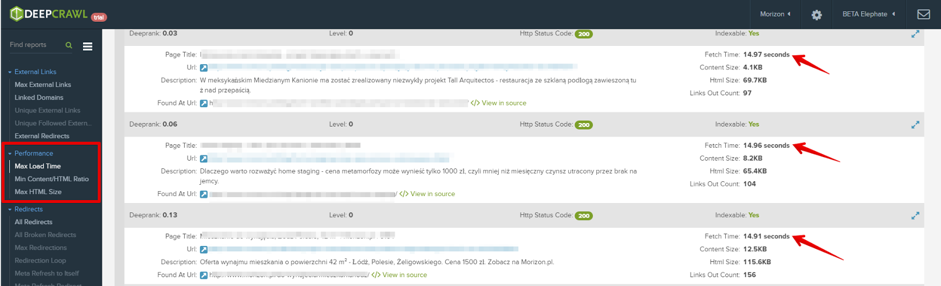
パフォーマンスの問題があるページを検出することが最初のステップです。ここで、GtmetrixやPageSpeed Insightのような無料のツールで実際に変更するべき内容に関する詳細な情報を得ることができます。
次に、クロールバジェットの最適化において非常に役立つもう1つの要素であるGZIP圧縮の使用についてご説明します。GZIPを活用することでサーバー上のファイルサイズを縮小できるため、サーバーからブラウザへのレスポンスがはるかに速くなります。GZIPはHTML、CSS、JavaScriptファイルに使用可能ですが、画像の圧縮には使用できません。
以下ではGZIPの機能と、サイトの高速化の結果をご紹介します。
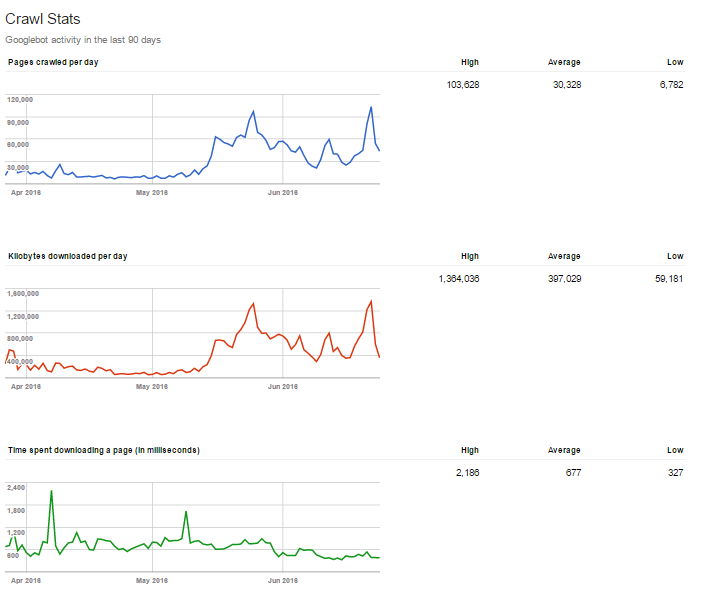
この結果はGooglebotはサーバーが低速化するまでクロールを継続するという、前述のGary氏の言及を裏付けています。つまり、サイトが軽く、早く読み込まれれば、その分スパイダーも長くクロールできるということになります。
サーバーログ分析
それでは、クロールバジェット最適化の効果を確認しましょう。これを行うためには、サーバーログとデータ分析に役立つソフトウェアが必要です。サーバーログにはサーバーに実行されたすべてのリクエストに関するデータが含まれています。ホストや日付、リクエスト先のURLパス、ファイルの重さなどの情報を得ることができます。ご存知の通り、このようなファイルは膨大なことが多々あります。サイトが頻繁に訪問されるほど、ファイル内により多くの行データが生成されるためです。EXCELを使用することもできますが、Splunkなどのサーバーログファイル分析に特化したソフトの使用をおすすめします。サーバーログ(英語)を分析すると、以下のような情報を得ることができます。
- Googlebotがサイトをクロールした頻度
- 最も頻繁に訪問されたページ
- クロールされたファイルの容量
この記事で紹介した情報があれば、ボットが正しくサイトをクロールしているか見極めることができます。また、ページでクロールバジェットが適切に使用されているかの確認に役立ちます。適切でない場合は、この記事の初めに戻って最適化を見直しましょう。
最後に
SEO業務で、クロールバジェットの最適化が習慣化することを願っています。これらの変更はすべて、ボットのクロールを効率化するだけでなく、サイトの高速化やナビゲーションの簡素化、不要なURLの削除とユーザーの満足度の改善に繋がるということを忘れないでください。

