
一般的なWebサーバーはログファイルに受信した全てのリクエストのログを蓄積しています。
Webサーバーのログファイルには、Googlebotへのページを含む各クライアントへ提供しているファイルの記録が含まれており、検索エンジンがサイトをクロールする方法に関するユニークな洞察を提供することができます。
しかし、ログファイルはアクセスも処理も困難なことが多いです。GooglebotをトラッキングするためにGoogleアナリティクスを活用することが、面倒なログファイルを扱うことなく検索エンジンのクロール解析を行う別の方法となります。
Webサーバーログファイル入門
Webサーバーからファイルがリクエストされる度に(つまりブラウザ経由でユーザーがページに訪問する、または検索エンジンがURLをクロールする)、ログファイルにテキスト出力が行われます。
テキスト出力にはそのリクエストが行われた日付、リクエストのIPアドレス、リクエストされたURLやコンテンツ、そしてブラウザのユーザーエージェントなどの詳細が含まれています。
188.65.114.122 –[30/Sep/2013:08:07:05 -0400] “GET /resources/whitepapers/ retail-whitepaper/ HTTP/1.1” 200 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)“
一般的に、新しいファイル名で新規ログファイルは毎日作られています。
ログファイルの活用
同じIPとユーザーエージェントからのリクエストを統合することで、個々のユーザーの行動をまとめることができます。ログファイルからの情報を処理し、サイトの各ページビューに細分化した行動履歴をレポートするソフトウェアがあります。サードパーティ製のアナリティクスパッケージソフトが登場する前は、この種のデータがWeb解析の主要な情報源でした。
ログファイル解析は、ユーザー行動に加え、クローラーに対して固有のページレベルの洞察を与えてくれます。
クローラーは基本的にJavaScriptをレンダリングしないため、ページビューは一般的なアナリティクスソフトウェアでは記録されません。ログファイルは、他のソースでは提供できないURL単位での検索エンジンのクロールデータを提供することができ、これはクロールをできるだけ効率的かつ効果的に行う目的でサイト構造を最適化する際に非常に役立ちます。
ログファイル解析を活用すると、価値が低いが活発に作動しているクローラーを検出し、それらをブロックすることでサーバーコストを削減できるという点でも便利だと言えます。 ユーザーエージェントにはなりすましが発生するので、IPアドレスの逆引きは、ボットが本物であると確認するために必要です。
非常に便利なものである一方、ログファイル解析にはたくさんの課題もあります。
ログファイル解析の課題
- サイズ:ログファイルはサイトのアクティビティの量に比例して数ギガバイトの容量に及ぶこともあるため、ダウンロードが遅くなったり、蓄積しておくのが難しくなったりする可能性があります。
- アクセス:サーバーへのFTPアクセス設定が必要になり、結果としてシステム全体のセキュリティが悪化することがあります。
- フォーマット:Webサーバーのように多様なフォーマットが存在する場合には対応が難しくなります。
- CDN:サードパーティのキャッシュサービスは一般的にログファイルを提供しておらず、複数のCDNを1つにマージすることは容易ではありません。
- 認証:ユーザーエージェントのなりすましが存在するため、検索エンジンのクローラーは逆引きを使って認証されなければなりません。
Googleアナリティクスのサーバーサイドでの書き換え
このユニバーサルアナリティクスの書き換えは、Googleアナリティクスアカウントにあるログファイルの情報を蓄積するために、リアルタイムでアクセスできるMeasurement Protocolを利用しています。
一旦書き換えが実行されると、再びログファイルを処理する必要が完全になくなります。しかし、Webサーバー上でシンプルなカスタムスクリプトを開発・運用して、それぞれのリクエストをモニタリングしていく必要はあります。
Webサーバーのスクリプトを開発、インストールできるスキルを持った人はかなり限られているため、通常は、実装においてサーバー管理者に問い合わせるべきです。
ユーザーエージェントがGooglebotの場合、そのスクリプトがGoogleアナリティクスのサーバーにHTTPリクエストを行い、通常はログファイルに蓄積される情報と同じ情報がリクエストURLにエンコードされる形で蓄積されていきます。
http://www.google-analytics.com/collect?uip=127.0.0.1&cs=page+title&tid=
UA-1234567810&dp=%2Ftest&dt=127.0.0.1+%28Mozilla%2F5.0+%28Macintosh
%3B+Intel+Mac+OS+X+10_9_5%29+AppleWebKit%2F537.36+%28KHTML%2C+
like+Gecko%29+Chrome%2F44.0.2403.157+Safari%2F537.36%29&dh=
example.com&cid=316c4790-2eaf-0133-6785-2de9d37163a1&
t=pageview&v=1
これはGoogleアナリティクスの情報をページビューとして記録します。
Measurement Protocolに関する詳細は、Googleのディベロッパーサイトをご覧ください。
こうした情報はメインとなるユーザーアカウントとは別のGoogleアナリティクスアカウントで保管するようにしましょう。
ページビューから、アクティビティのレベルやページレベルでの詳細を確認してください。
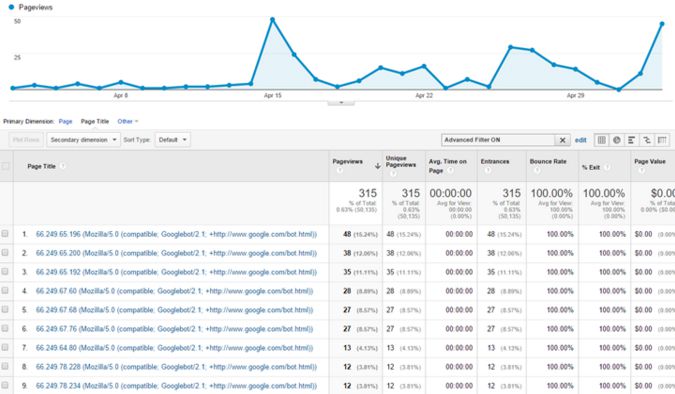
Googleアナリティクスは表示・フィルタリングされるフィールドをリアルタイムで制限しています。クロールにおけるリアルタイムデータを取得するには、タイトル部分にユーザーエージェントの情報を含めるようにしてください。
リクエストのIPアドレスを追加することも、正規のGooglebot (66.249から始まる)のアクティビティを簡単にフィルタリングするための便利な手法です。
カスタムディメンションにはリクエストの時間などの情報を追加してください。
GooglebotをトラッキングするためにGoogleアナリティクスを活用することで、ログファイルを精査する必要がなくなるため、検索エンジンのクロールを効率よく分析していくことができます。
ログファイル解析の詳細については、 BuiltVisible社のログファイル解析:究極のガイド(英語)をご覧ください。
または、DeepCrawlを活用いただければ、お客様のサイトをGooglebotがどのように見ているか把握することができ、更にGoogleアナリティクスアカウントと連携すればデータを比較していくこともできます。DeepCrawlの詳細はこちらです。

